
Белорусский стартап, занимающийся предсказанием виральности текстов, выпускается из финского акселератора Startup Sauna и рассчитывает привлечь первые инвестиции. Основатели Exponenta рассказали dev.by о создании проекта, разработке необычной предиктивной модели, первых клиентах и планах.

Алгоритмы распознают виральный потенциал текста «лучше любого редактора»
— Как возникла идея предсказывать виральность текстов?
Дарья Мински, co-founder/CEO Exponenta: Как основатель kyky.org, я постоянно думала, как нам расширить аудиторию. Рынок рекламы в Беларуси настолько мал, что на нишевых медиапроектах заработать здесь фактически невозможно. Когда мы презентовали идею KYKY на «Деловом интернете-2011», Юрий Гурский сказал нам: «Если заработаете на собственный офис, будете героями». С офисом-то получилось, но дальше дело не продвигалось.
Зато в какой-то момент мы начали довольно регулярно производить виральные материалы: их репостили на Adme, распространяли по всему русскоязычному интернету. И я задумалась: можно ли выделить какие-то паттерны, согласно которым тексты становятся вирусными, и воспроизводить их в последующих материалах? По совету друзей я встретилась с исследователем данных, погружённым в тему анализа текстов — к моему удивлению, он представлял, как создать модель предсказания виральности. С той встречи и началась Exponenta: мой собеседник, Дима, стал сооснователем стартапа.
Дмитрий, co-founder/CTO Exponenta: Сначала мы попытались определить само понятие виральности. Оказалось, это нетривиальная задача: редакторы и паблишеры, с которыми мы общались, высказывали абсолютно разные мнения.
Остановились мы на том, что виральность — это максимальное покрытие аудитории, существующей у издания. Например, статья публикуется в закрытой группе в Facebook, в которой состоит 100 тысяч пользователей — значит, у неё есть естественный потолок в 100 тысяч уникальных просмотров. Мы прогнозируем, насколько контент может приблизиться к этому потолку.
— Получается, у разных площадок — разные критерии виральности?
Дарья: Верно. Если на условном TechCrunch виральным будет считаться текст, просмотренный 100 тысяч раз, то для условного BuzzFeed речь уже о миллионе просмотров.
Дмитрий: Когда мы определились, какое событие предсказываем, стали разбираться, какие факторы могут на него влиять. Входной список был огромным: мы начали с нескольких сотен факторов, со временем их число выросло до тысяч. Кроме того, в машинном обучении часто работают трюки с составными факторами. Скажем, если отдельно подсчитать количество слов, отдельно — количество предложений в тексте, то сильного влияния на виральность нету. А если взять произведение этих показателей, получится удачный фактор. Всё это нужно было проверить.
Дарья: Сейчас прототип Exponenta умеет описывать конкретные англоязычные тексты до мельчайших деталей. Мы изучили около десяти тысяч факторов. И если изначальная точность предиктивной модели была немногим выше монетки — то есть едва ли превышала по качеству чутьё опытного редактора — то сейчас для некоторых платформ точность предсказания достигает 80%. Это значит, что наша модель видит виральный потенциал текста лучше любого редактора.
Дмитрий: Но предсказать событие, исходя из имеющихся данных, и объяснить людям, почему оно должно произойти — кардинально разные задачи. Изначально мы концентрировались на том, чтобы максимально точно и красиво решить задачу прогноза, а теперь объясняем человеческим языком, почему этот прогноз должен сработать. Конечному потребителю важно иметь не голое число, а осмысленный, применимый на практике инструмент.
Издатели не всегда рады
— Как работает модель предсказания виральности?
Дмитрий: Для обучения модели мы используем исторические данные платформы: собираем все опубликованные на ней материалы, анализируем их по ряду признаков, соотносим полученные показатели с реальной популярностью текстов. Предиктивный алгоритм принимает неопубликованный материал и описывает его в том же пространстве признаков. По положению в этом пространстве можно оценить потенциальную успешность текста, а также дать рекомендации, что в нём следует изменить, чтобы повысить виральный потенциал.
— Влияние одного и того же фактора может отличаться от платформы к платформе?
Дмитрий: Безусловно. Мы не пытаемся решить глобальную проблему — мы привязываемся к данным конкретных платформ, чтобы сделать решение практически применимым. Многие факторы отсеиваются в процессе исследований. В первой модели было задействовано 198 показателей, во второй учитывается 125, но у нас остаётся длинный список «на проверку».
Да, мы перебрали далеко не все факторы, но при существующей точности в 80% возникает другой вопрос: сколько конечному потребителю будут стоит 2-3% улучшения точности прогноза? Эти проценты могут резко замедлить работу модели, сделать более сложной подготовку данных, увеличить период внедрения либо даже потребовать доработок на стороне пользователя.
Дарья: Сейчас мы проверяем все эти нюансы на данных клиентов. Эксперименты идут на пяти платформах, демо-версия запущена у нашего первого клиента, в планах — запуск демо на TechCrunch. Модель работает, и предсказания получаются вполне адекватными. Но чтобы её доработать, нам нужно больше исторических данных. Для обучения модели нужно не менее нескольких тысяч публикаций.
Дмитрий: У нас в стране ни у кого нет опыта подготовки, публикации и сопровождения контента на по-настоящему масштабном уровне — ближе к миллиарду просмотров в месяц. В мире такие гранды есть, но экспертизой они с нами делиться не спешат. Самостоятельно парсить данные с сайтов мы тоже не можем: по законодательству западных стран, это запрещено. Приходим к издателям, вежливо просим данные, но, к сожалению, нам не всегда рады.
Бывают проблемы и с достоверностью данных: у нас есть объективные подозрения, что цифры просмотров, отображённые на странице, не всегда соответствуют реальному количеству читателей. Разумеется, не каждый производитель контента готов признать, что «накручивает» просмотры.
Авторский стиль сложно описать цифрами
— Как вы измеряете точность сделанных предсказаний?
Дмитрий: Всё просто: текст публикуется, и через фиксированный промежуток времени (например, спустя неделю после публикации) мы сравниваем реальные показатели его популярности с нашим прогнозом. Целевая переменная (просмотры, лайки, репосты) для нас не принципиальна, её можно поменять по запросу конкретного клиента: пока у Exponenta нет финального коробочного решения. Так или иначе, работу с каждой платформой мы начинаем с полного списка факторов — с тех самых 10 тысяч. Собираем и обрабатываем исторические данные, запускаем алгоритм «на ночь» — и с утра у нас остаются условные 200 факторов, важных для предсказания.
В ваших планах — создание «соавтора», который сможет давать конкретные рекомендации по изменению текстов с низким потенциалом виральности.
— Как будет выглядеть система рекомендаций?
Дмитрий: Базовый набор рекомендаций уже существует — прямо сейчас он на стадии тестирования. Любые два текста можно сравнить между собой по каждому из признаков в нашем пространстве, а результат описать числовыми метриками. Сравнивая метрики, мы можем получать эти базовые рекомендации: «Параметр X следует сделать большим, Y нужно уменьшить».
Но использовать такой вариант на практике не выйдет. Если средняя длина предложения в очень успешном материале — шесть слов, и этот фактор влияет на виральность, то это ещё не повод переписывать каждый текст так, чтобы во всех предложениях слов было ровно шесть. Чтобы рекомендации имели практический смысл, все числовые метрики нужно перевести на язык редакторов, дать подробные объяснения, как и почему та или иная метрика влияет на виральность.
И здесь возникает новая проблема: каждый редактор понимает слово «рекомендация» по-своему. Поэтому сейчас мы пытаемся решить задачу в обратном направлении: расспрашиваем редакторов, какие рекомендации будут для них иметь практическую ценность, сводим разные мнения к общему знаменателю, формализуем их, переводим на язык чисел и отправляем на следующий этап исследования.
— Связана ли виральность с качеством материала?
Дарья: Мы уверены, что связана. Нас не интересует чистая кликабельность текста — наоборот, мы планируем добавить в проект функционал распознавания кликбейта и фейковых новостей. Чтобы материал стал виральным, читатель должен не просто перейти на него по ссылке с заголовком и лидом, но и прочитать этот текст, и настолько впечатлиться, чтобы лайкнуть и зашарить его.
— Способна ли модель дать рекомендации, которые не «высушат» текст и не уничтожат авторский стиль?
Дарья: Мы не подстраиваем автора под некое общее понимание виральности: модель обучается на исторических данных, которые включают тексты его блога, сайта, портала, для которого он пишет. То есть мы даём рекомендации, которые помогут расширить охват той самой аудитории, для которой автор создавал контент и раньше.
Дмитрий: Понятно, что модель не должна обезличивать автора или аудиторию, иначе рекомендации потеряют всякий смысл. Однако авторский стиль сложно описать цифрами, и даже на естественном языке это очень размытое понятие. К тому же если на большой платформе можно собрать достаточное количество исторических данных, то по отдельному автору их будет значительно меньше, а это снизит точность предсказания.
Дарья: Одна из наших будущих задач — на основе анализа статьи предлагать лучшую площадку для её публикации. Это серьёзный технологический вызов, но мы уверены, что эту задачу может решить крепкий solution architect. Если кто-то знает, как это сделать лучше всего, пусть обращается к нам: мы прямо сейчас ищем человека, который сможет понимать продукт на глубоком уровне и будет готов работать в спарринге с исследователем данных высокого уровня.

В поисках посевного раунда «до полумиллиона долларов»
— Как Exponenta попала в акселератор Startup Sauna?
Дарья: Всё началось с TechMinsk, и за это я очень благодарна ребятам из Imaguru: это они убедили меня участвовать в акселерационной программе. В то время я ещё не планировала широко представлять стартап: у нас не было продукта как такового, и мне казалось, что выходить на публику пока рано. По факту, мы запустили продукт для клиентов совсем недавно, но за счёт участия во многих конференциях (Venture Day, LOGIN, Latitude59) уже успели заработать кое-какую известность. В наших ближайших планах — конференции DiG Publishing в Лиссабоне и Slush в Хельсинки.
В Startup Sauna мы попали после минской сессии Warm Up в этом марте. Создатели акселератора — те же ребята, которые проводят Slush, крупнейшую европейскую стартап-конференцию.
Они требуют от стартапов высокого уровня: в процессе отбора финны объездили всю Восточную и Северную Европу, отслушали около 700 питчей, а выбрали только 14 команд. Это серьёзный фильтр, и инвесторы воспринимают его как знак качества. Для нас самих это тоже серьёзный шаг: за месяц в Хельсинки мы стали совсем по-другому понимать продукт, здорово поработали над питчем, стали увереннее в себе — и теперь готовы привлечь посевной раунд, над чем сейчас активно работаем.
— Есть конкретные предложения от инвесторов?
Дарья: Есть. Сейчас мы пытаемся встретиться с как можно большим количеством потенциальных партнёров, выслушать все предложения. Мы рассчитываем получить посев до полумиллиона долларов, но ищем исключительно «умные деньги»: инвесторов с экспертизой в AI, data science, медиа и рекламе.
16 мая в акселераторе в Хельсинки демо-день, и это ещё одна возможность максимально конкретно пообщаться с представителями профильных бизнесов.
Пока Exponenta даже не зарегистрирована как компания — мы ждём, пока определится первый инвестор, а вслед за этим определимся и со страной регистрации.
Через несколько лет будет невозможно создавать контент без подобных инструментов?
— На какой рынок в первую очередь направлен ваш продукт? Издательский?
Дарья: Не совсем. Мы сотрудничаем с паблишерами, с их помощью мы дорабатываем продукт, но в качестве основной категории клиентов мы рассматриваем агентства нативной рекламы. Сейчас это один из самых быстрорастущих рынков во всей рекламной индустрии — а рынок паблишинга стремительно падает, и, боюсь, его уже трудно спасти.
Прорабатывать монетизацию планируем уже после того, как завершим рекомендательную систему: именно для работы над ней мы и хотим получить первые инвестиции. Сейчас мы работаем в B2B-секторе, но с рекомендациями сможем переместиться и в B2C — как, например, украинский стартап Grammarly, который недавно получил 110 миллионов инвестиций. Мы даже используем схожие технологии — только они работают с грамматическим аспектом текста, а мы — с аспектами популярности, трендовости и читабельности.
Думаю, самой интересной для нас будет freemium-модель: предсказание виральности предоставляется бесплатно, а за рекомендации нужно заплатить. Есть мысли и о внедрении нашего продукта на блог-платформы: например, авторы постов смогут видеть наш прогноз виральности и несколько простейших рекомендаций, а для более подробного разбора должны будут оплатить подписку.
— Есть ли у проекта прямые конкуренты?
Дарья: Есть компании, которые делают A/B-тесты материалов и отслеживают изменение их популярности в реальном времени. Но, насколько мы знаем, других проектов, которые работают с текстом до его публикации, на рынке нет. Инвесторы и менторы, с которыми я общалась, тоже говорят, что не слышали ни о чём подобном. У Buzzfeed и Mashable есть похожие продукты, Pound и Velocity. Но они разработали эти инструменты для собственных платформ и рекламодателей, и вряд ли сделают их общедоступными. Мы совершенствуем их технологии и находим им новое, более широкое применение.

— Почему никто не занял эту нишу?
Дмитрий: Думаю, многие пытались и пытаются сделать что-то подобное, но по разным причинам этого не афишируют. Возможно, у кого-то из крупных паблишеров есть подобные продукты для внутренних целей. А может, раньше просто было не время для таких проектов. За последние лет пять машинное обучение совершило большой скачок: появилось множество подходов, методик, готовых библиотек, доступных обычным людям, не имеющим доступа к космическим вычислительным мощностям — таким, как я.
Очень важно, что на старте нам здорово помогли с доменной экспертизой: без неё мы использовали бы в прогнозах только очевидные факторы, а значит, не смогли бы добиться нужного качества.
С другой стороны, всегда есть соблазн повернуть прогнозные модели исключительно в точность, не учитывая факторов, понятных человеку. Обучить модель, составить и проверить список возможных факторов — только полдела. Нужно уметь преподнести результаты аналитики людям, принимающим решения. Мы вложили много усилий, чтобы перейти от цифр к чему-то, что можно «потрогать руками». Если вы не объясняете результаты работы прогнозных моделей человеческим языком, вы их никому не продадите.
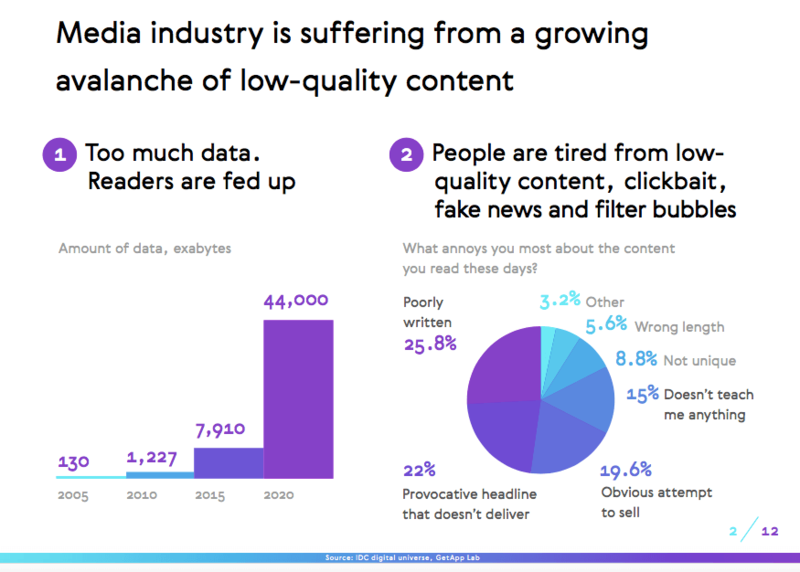
Дарья: Мне кажется, что без инструментов, подобных нашему, через пару лет создавать контент будет невозможно — иначе он будет незаметным в огромной сети. Общее количество информации удваивается каждые два года, и уже сейчас продвинуть материал в интернете — очень сложная задача. И наша далёкая цель — стать стандартным AI для всех, кто постоянно создаёт контент.







Релоцировались? Теперь вы можете комментировать без верификации аккаунта.