
Андрей Кутейко
March 22, 2016

Полнотекстовый поиск - одна из самых распространённых задач, с которой придётся столкнуться при разработке сайта. Такие популярные РСУБД как MySQL и PostgreSQL уже содержат встроенные поисковые механизмы. Но, к сожалению, их реализация оставляет желать лучшего. Простая разбивка на слова не подходит для языков с флексиями, таким как русский.
На выручку приходят специализированные инструменты, хорошо разбирающиеся в разных языках. Зарекомендовал себя поисковый сервер Sphinx, поддерживающий большое количество языков. Есть в Sphinx даже такая интересная возможность как фонетический поиск. Это значит, что можно искать такие слова как: «моск», «афтар», «превед» и находить «мозг», «автор», «привет».
К сожалению, за возможность искать (и находить) произвольный текст приходится расплачиваться гибкостью.
Традиционная схема работы с поисковым сервером такая:
программа-индексатор обращается напрямую к базе данных, сканнирует нужные таблицы и строит индексные файлы;
запускается поисковая служба (демон);
приложение обращается к службе с поисковым запросом и получает результат.
Если же данные обновляются (а скорее всего так и есть), то индексы нуждаются в обновлении. И тут схема далека от идеала:
программа-индексатор строит новый индекс в промежуточных файлах;
посылается сигнал поисковой службе, и она переключается на новые индексы;
старые индексы удаляются.
Индексатор нужно запускать самостоятельно (cron) и это приводит к тому, что данные попадают в поисковые индексы не сразу. Во время обновления индекс требует в два раза большего места на диске. Есть возможность делать инкрементальные обновления, но они требуют дополнительной процедуры слияния индексов. Также придётся как-то определять, какие данные уже проиндексированы, а какие ещё нет. Тут можно придумать много всяких способов: запоминать последний добавленный id, булево поле и т. п. Так или иначе, это потребует написания какого-то кода. Если ещё вспомнить, что данные могут не только добавляться, но и обновляться и даже удаляться, то рисуется безрадостная картина.
К счастью, выход есть. Sphinx предлагает такую замечательную возможность, как real-time-индексы. Основное отличие RT-индексов в том, что они не требуют индексатора и позволяют добавлять, обновлять и удалять данные обращаясь непосредственно к поисковой службе.
В традиционной схеме индексатор самостоятельно обращается к базе данных. Здесь же приложение вынуждено обновлять данные. Нельзя ли совместить эти две схемы? Нельзя ли переложить эту работу на базу данных?
Оказывается, можно. Современные РСУБД позволяют отслеживать изменения в данных и реагировать на них соответственно (так называемые триггеры). То есть заботу об обновлении поискового индекса можно переложить на триггеры.
К несчастью триггеры не могут устанавливать сетевых соединений и всю чёрную работу придётся делать в пользовательских функциях (UDF — user-defined function). В случае PostgreSQL это потребует написания разделяемой библиотеки. Можно было бы написать например на Python, но мы же хотим максимальной производительности!
От слов к делу
Расширение pg-sphinx для PostgreSQL позволяет обновлять индексы непосредственно из триггеров, хранимых процедур и любых других мест, где возможен вызов функции. Например, нижеприведённый SQL-код обновляет (или вставляет, если её ещё не было) запись №3 в индексе blog_posts.

Раз уж у нас есть расширение, почему бы не пойти дальше? Можно кроме обновления данных делать и поисковые запросы прямо из базы данных.

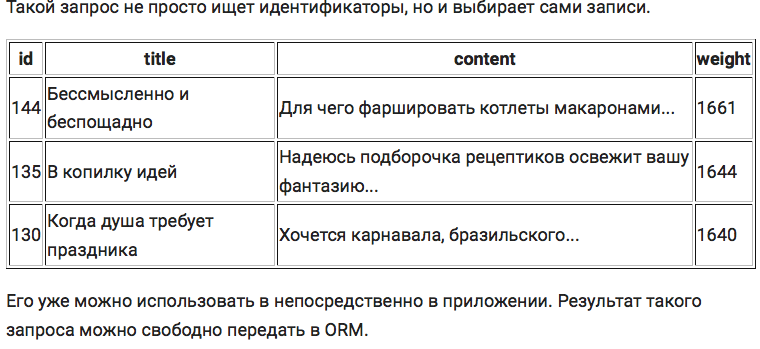
Итого
Что получилось?
Избавились от запуска индексатора, нет пиков нагрузки на базу данных.
Данные в поисковом индексе всегда актуальны.
Приложение не заботится об обновлении индексов, этим занимается сама РСУБД.
Поиск выполняется на стороне сервера баз данных и приложению не нужно поддерживать соединение с поисковым сервером.
Поисковые запросы можно произвольным образом смешивать между собой и с запросами к самим данным.
Чего не хватает? Что не реализовано?
Сделано неявное предположение, что все данные хранятся в кодировке UTF-8 и поддержка других кодировок не сделана намеренно.
Подсветка найденных слов не реализована.
Перенастройка подключения к поисковому серверу требует перекомпиляции.
Не реализованы такие функции как транзакции (сейчас AUTOCOMMIT по-умолчанию) и пользовательские функции (нужно разворачивать выражения явно).
...
Однако, это расширение можно использовать уже сейчас в большинстве простых приложений, несмотря на недостатки.







Релоцировались? Теперь вы можете комментировать без верификации аккаунта.