
 Недавно cостоялась 4-ая встреча PHP User Group Minsk в коворкинге ME100. Такие встречи проходят раз в месяц, а их организаторами являются минские PHP-разработчики. Цель таких встреч — поделиться опытом и знаниями, посмотреть, как похожие процессы построены в других командах/компаниях. Это скорее неформальные мероприятия, которые проходят в режиме свободной дискуссии и в которых принимают участие PHP-разработчики из разных IT-компаний в Минске.
Недавно cостоялась 4-ая встреча PHP User Group Minsk в коворкинге ME100. Такие встречи проходят раз в месяц, а их организаторами являются минские PHP-разработчики. Цель таких встреч — поделиться опытом и знаниями, посмотреть, как похожие процессы построены в других командах/компаниях. Это скорее неформальные мероприятия, которые проходят в режиме свободной дискуссии и в которых принимают участие PHP-разработчики из разных IT-компаний в Минске.
Основными темами на 4-ой встрече PHP User Group Minsk, которая прошла в октябре, были Symfony, Continuous Integration, NodeJS и DDD.
В своем докладе Антон подробно рассказал о том, как код 15-ти разработчиков Startup Labs два раза в неделю выкатывается на продакшен: «Мы разрабатываем B2B систему, не очень большую, но и не очень маленькую. Проект длится уже полтора года, и в разное время над ним работали от 4 до 15 разработчиков (сейчас 15). Трафик у нас небольшой, но дорогой, данных тоже не очень много — 15 гигабайт. Незапланированный downtime нам обходится дорого (однако есть maintenance window), т.е. мы можем позволить себе небольшой запланированный downtime. Баги на продакшене нам тоже обходятся дорого, потому что у нас не соцсеть: люди делают бизнес c помощью нашей системы и просто уйдут к конкурентам, если увидят, что у нас все нестабильно.
Технологии, которые мы используем:
- PHP 5.4;
- Java 7;
- PostgreSQL для БД;
- RabbitMQ как шина сообщений, соединяющая все компоненты между собой.
Примерный список фреймворков:
- в Java части — Hibernate и JUnit;
- в PHP части — Symfony 2, Silex для каких-то мелких компонентов, Behat для функциональных тестов, PHPUnit для юнит-тестов.
Мы любим Agile и основные принципы берем из него:
- делаем маленькие изменения;
- часто поставляем их клиенту;
- рано принимаем фидбек.
На пути становления наших процессов были определенные вещи, от которых мы по тем или иным причинам осознанно отказались.
1. В первую очередь это фиче-бранчи. Вообще, как мне кажется, фиче-бранчи очень слабо вяжутся с идеей Continuous Integration. Я бы даже сказал: либо фиче-бранчи, либо CI. Проблема в том, что код в фиче-бранче не интегрируется с остальным кодом, поэтому может сильно расходиться с кодом внутри других фиче-бранчей, даже если регулярно к нему подмерживается мастер.
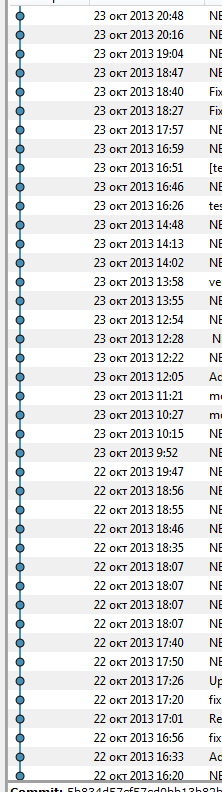
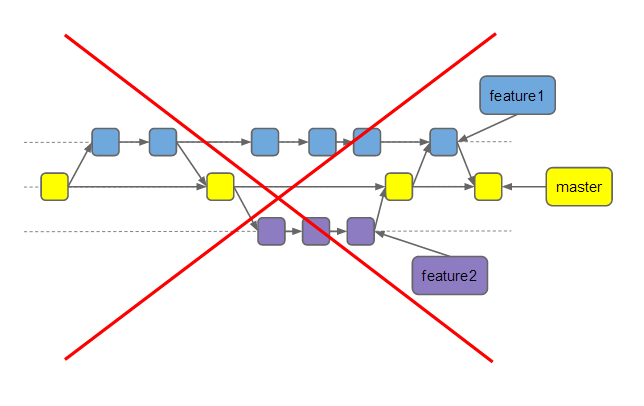 Второй аргумент против фиче-бранчей — это то, что не всегда можно понять, что же происходило уже иногда даже на следующий день. Ниже на скриншотe — история гита проекта другой команды, состоящей примерно из 15 девелоперов и верстальщиков. Разобраться в каком-то нетривиальном кейсе в такой истории получается очень сложно.
Второй аргумент против фиче-бранчей — это то, что не всегда можно понять, что же происходило уже иногда даже на следующий день. Ниже на скриншотe — история гита проекта другой команды, состоящей примерно из 15 девелоперов и верстальщиков. Разобраться в каком-то нетривиальном кейсе в такой истории получается очень сложно.
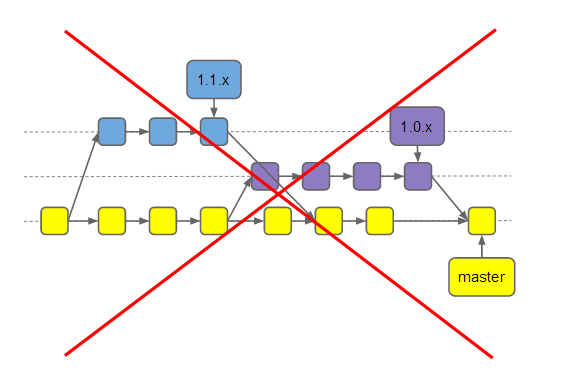
2. Далее мы отказались от релиз-бранчей. Они нужны, если надо поддерживать несколько версий ПО. Обычно при разработке продукта это не нужно, но многие, наверное, смотрят на популярные библиотеки и делают так, как они.
 3. Также мы отказались от всяких develop-бранчей. Часто при создании проекта даже на двух девелоперов создают сразу staging и master. Разработку ведут в develop, а потом мержат это все в другие бранчи. Для нас это оказалось избыточно, и мы не нашли в этом никакой пользы.
3. Также мы отказались от всяких develop-бранчей. Часто при создании проекта даже на двух девелоперов создают сразу staging и master. Разработку ведут в develop, а потом мержат это все в другие бранчи. Для нас это оказалось избыточно, и мы не нашли в этом никакой пользы.
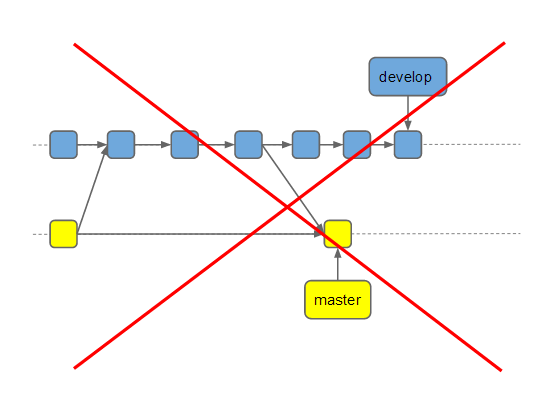 4. Мы не делаем релиз-теги. Хотя это не мешает работе и не требует сложной поддержки, пока что необходимости в них у нас тоже не было.
4. Мы не делаем релиз-теги. Хотя это не мешает работе и не требует сложной поддержки, пока что необходимости в них у нас тоже не было.
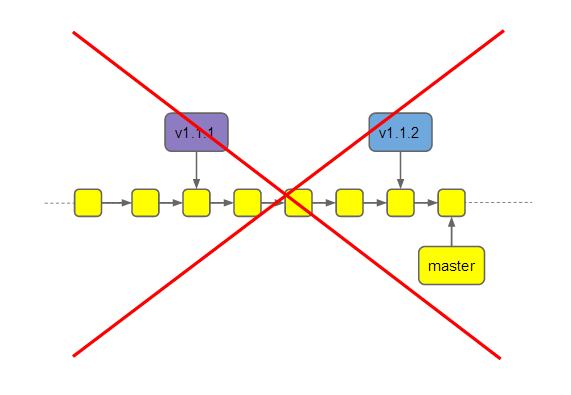 5. В отдельности можно сказать, что мы не используем git-flow. Я вообще не понимаю, почему так много людей его боготворят. Это огромный оверкилл, заставляющий даже плагины к гиту использовать, потому что без них работать уже неудобно.
5. В отдельности можно сказать, что мы не используем git-flow. Я вообще не понимаю, почему так много людей его боготворят. Это огромный оверкилл, заставляющий даже плагины к гиту использовать, потому что без них работать уже неудобно.
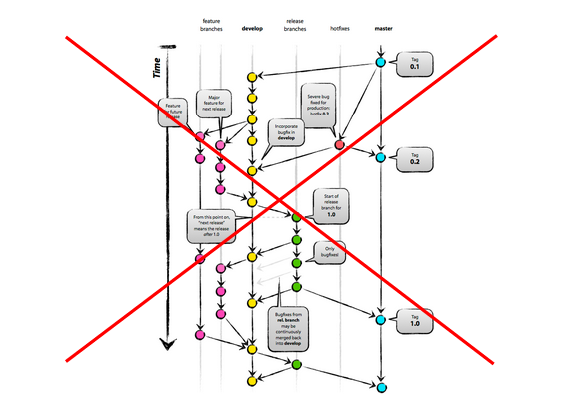 Что мы используем, так это Continuous Integration. Что это значит для нас:
Что мы используем, так это Continuous Integration. Что это значит для нас:
- девелопер должен каждый день интегрироваться с основной (и единственной) веткой разработки;
- каждый коммит собирается на билд-сервере;
- на каждый билд выполняются все автотесты;
- красные билды надо фиксить быстро.
Это все в идеале. Иногда случаются ситуации, когда девелоперы не интегрируются по три дня. Иногда бывает, что билд целый день красный. Но мы стремимся к этим принципам.
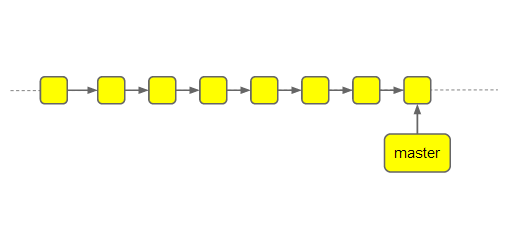
Мы используем один бранч-мастер. Все девелоперы коммитят в него, с него же собираются билды, которые потом идут на все серверы, в том числе и на продакшен. Ниже можно видеть, как это примерно выглядит у нас в истории.
|
|
Важный момент с Continuous Integration — это то, что ты постоянно должен интегрировать свой код с мастером. Понятное дело, что не все фичи делаются меньше дня. Для таких случаев есть интересный подход: Branch By Abstraction. Первым делом девелопер коммитит выключатель для фичи, который выключен по умолчанию. Далее он может постоянно интегрироваться с мастером, не боясь что-то сломать. Его код может уже быть (а иногда не раз) задеплоен в выключенном состоянии на продакшен. Потом, когда фича подходит к концу, она включается и отправляется в QA, которые ее проверяют, и если все хорошо, то уже следующий релиз ее включит на продакшене.
Нет смысла говорить о CI без автотестов. Автотесты мы очень любим и активно используем. QA у нас пишут Behat сценарии до разработки фичи или во время ее разработки, а девелоперы их имплементят. Мы стараемся абсолютно каждую фичу покрывать сценариями. Таким образом, получается отличный большой пак регрессионных тестов, который позволяет нам достаточно просто и безболезненно проводить рефакторинг.
Вот несколько цифр с проекта:
У нас уже 1000 Behat сценариев (это не включая юнит-тесты, которых у нас поменьше). Билд длится в среднем 15 минут (включая прогон всех функциональных тестов). У нас два достаточно мощных билд-сервера и примерно 15 билдов в день. Нам важно, чтобы время билда было минимальным, тесты занимают бóльшую часть времени билда, поэтому мы постоянно работаем над их ускорением.
Два раза в неделю мы деплоимся на продакшен. Деплой запускается вручную. У нас для этого собирается мини-команда из девелопера, менеджера и архитектора, которая нажимает на кнопку и проверяет потом, все ли в порядке. Дополнительно у нас есть сервер nb-prod — он инкрементально обновляется вместе с продакшеном, это песочница для других команд, которым нужно интегрироваться с нашим продуктом.
На данный момент в нашем процессе деплоя на продакшен нету стратегии поведения во время возникновения каких-то проблем. Мы не можем принципиально откатиться назад. На самом деле это не так уж страшно, потому что кейсы, когда что-то идет не так, крайне редки: очень большая часть проблем с деплоем отсекается на этапе теста миграций на базе продакшена».
Более подробно о том, как происходит сам процесс билда и какие фазы он в себя включает, можно будет узнать в нашем следующем посте.
Посмотреть полную презентацию можно здесь.







Релоцировались? Теперь вы можете комментировать без верификации аккаунта.