
Собственные чипы Google для машинного обучения, оптимизированные для работы с фреймворком TensorFlow, работают до 30 раз быстрее существующих аналогов, сообщает TechCrunch со ссылкой на отчёт компании.

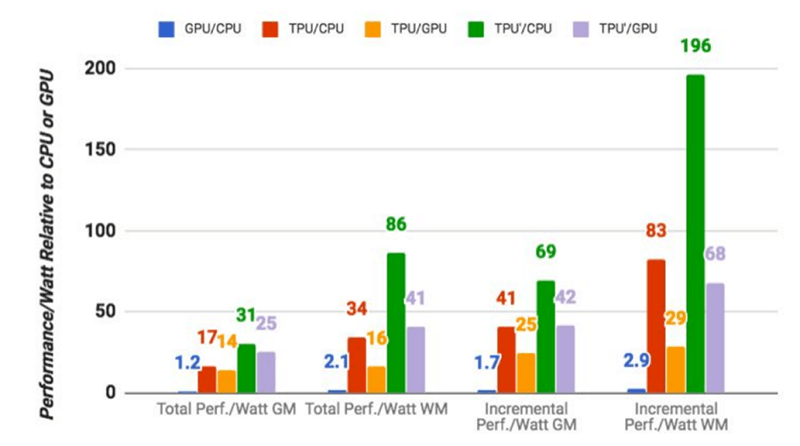
По данным Google, TPU (TensorFlow Processing Unit) производства компании выполняют стандартные задачи машинного обучения в среднем в 15-30 раз быстрее, чем традиционная комбинация GPU/CPU («стандартным» для Google стало использование процессоров Intel Haswell и графических карт Nvidia K80).
Ещё одним преимуществом TPU является повышенная энергоэффективность — устройство обеспечивает выполнение от 30 до 80 раз большего количества операций в расчёте на один Ватт.
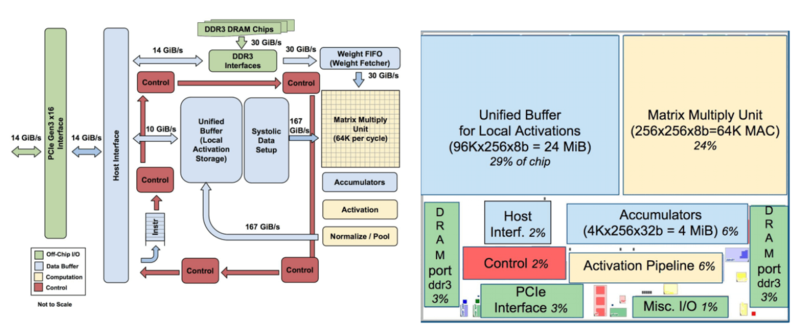
Традиционно устройства оптимизируют для работы свёрточных нейронных сетей, однако в практике Google на них приходится лишь около 5 процентов работы, в то время как большинство приложений использует многослойные перцептроны. Разработка архитектуры с учётом выполняемых задач оказалась весьма эффективной.
В Google задумались о повышении эффективности дата-центров с помощью разработки собственного «железа» ещё в 2006 году, но активно занялись вопросом лишь в 2013-м.
«Мы поняли, что динамические нейронные сети станут настолько популярны, что удвоят потребность в вычислительных мощностях, удовлетворить которую с помощью традиционных процессоров было бы очень дорого», — пишет один из исследователей.
Задачей разработчиков новой архитектуры стало десятикратное улучшение эффективности по сравнению с графическими процессорами — и этого удалось достичь.
Хотя компания вряд ли сделает TPU доступными другим пользователям, в Google уверены, что их разработки будут использованы, чтобы создать процессоры, которые «смогут поднять планку ещё выше».







Релоцировались? Теперь вы можете комментировать без верификации аккаунта.