
 Есть мнение, что самые крутые разработчики ПО работают вовсе не в Google или Facebook — они работают в NASA. Пока остальные СМИ постят пятничных котиков, мы публикуем статью о том, как создавалось надежное программное обеспечение для марсохода Curiosity, потому что мы верим в наших читателей — ведь если вы не сможете одолеть весь этот текст без купюр за сегодня, то впереди еще все выходные! (Видео доклада, по которому была подготовлена эта статья.)
Есть мнение, что самые крутые разработчики ПО работают вовсе не в Google или Facebook — они работают в NASA. Пока остальные СМИ постят пятничных котиков, мы публикуем статью о том, как создавалось надежное программное обеспечение для марсохода Curiosity, потому что мы верим в наших читателей — ведь если вы не сможете одолеть весь этот текст без купюр за сегодня, то впереди еще все выходные! (Видео доклада, по которому была подготовлена эта статья.)
5 августа 2012 года в 22:18 по тихоокеанскому времени крупный марсоход Curiosity (это название переводится с английского как «Любопытство» — прим. пер.) совершил мягкую посадку на красной планете. Поскольку скорость передачи информации (как и скорость света) имеет конечное значение, датчики на Земле зарегистрировали успешную посадку аппарата лишь спустя 14 минут, в 22:32. Разумеется, все функции марсохода, а также космического корабля, доставившего этот аппарат к месту назначения в 56 000 000 километров от Земли, управляются программным обеспечением. В этой статье рассмотрены меры предосторожности, предпринятые командой разработчиков ПО из ЛРД (лаборатории реактивного движения в составе НАСА) для обеспечения максимальной надежности этого ПО.
Основные тезисы
- Программное обеспечение, обеспечивающее работу межпланетного космического корабля, должно соответствовать высочайшим стандартам надежности. Малейшая ошибка может привести к провалу всей миссии и потере уникальной возможности расширить горизонты человеческих познаний.
- Экстраординарные меры обеспечения работоспособности предпринимаются при проектировании как аппаратного, так и программного обеспечения. Кроме того, должна быть возможность отладки и ремонта системы, работающей на расстоянии миллионов километров от вас.
- Выверенные методы работы позволяют выявлять в очень сложных системах потенциальные возможности возникновения условий гонки и взаимных блокировок. Новые методы проверки моделей позволяют автоматизировать процесс верификации.
Чтобы организовать экспедицию на Марс, требуется достаточно мощная пусковая установка, позволяющая преодолеть притяжение Земли. На Земле марсоход Curiosity весил 900 кг. На Марсе вес аппарата составляет всего 337,5 кг, так как Марс меньше Земли. Curiosity отправился в путь, находясь на верхушке огромной ракеты-носителя Атлас V 451. Кроме самого марсохода, на борту ракеты находилось топливо и различные детали, необходимые для экспедиции. В результате общий стартовый вес ракеты составил целых 531 000 килограммов, что в 590 раз превышает вес самого марсохода.
Но через два часа после старта большинство ступеней ракеты-носителя уже отцепились от основного корабля. К этому моменту на ракете остались только доставочная часть, защитный кожух, где находится большой парашют; посадочная ступень, оснащенная сложным механизмом «небесный кран», сам марсоход и крупный теплоизолирующий экран (см. рис. 1).
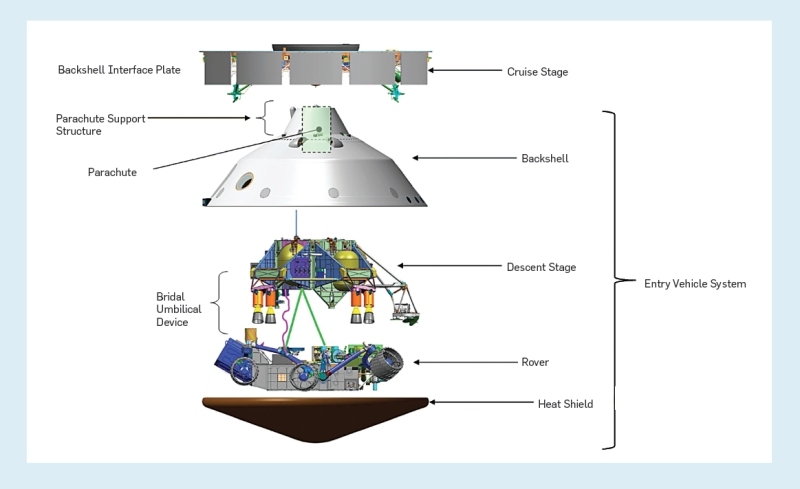
Рисунок 1. Детали космического аппарата
Доставочная часть была оборудована солнечными батареями, которые должны были питать космический корабль в ходе его девятимесячного пути к Марсу. Также в доставочную часть входил звездный датчик, оптимизировавший навигацию, и рулевые двигатели, выполнявшие небольшие корректировки курса. Все вспомогательное оборудование было отброшено примерно за 10 минут до того, как аппарат вошел в марсианскую атмосферу.
На поверхность планеты приземлилась последняя часть многоступенчатого аппарата — все то, что находилось в кожухе и было защищено теплоизолирующим экраном. Сам этот кожух был довольно велик — в нем мог уместиться небольшой автомобиль. У спускаемого аппарата был собственный комплект рулевых двигателей, корректировавших его курс в процессе входа в марсианскую атмосферу на сверхзвуковой скорости. На данном этапе от защитного кожуха отстрелилось несколько крупных кусков балласта (весом около 320 кг), что позволило изменить центр тяжести при посадке. Посадка была совершена по команде главного компьютера марсохода, который и координирует всю исследовательскую операцию.
Примерно за три минуты до контакта с грунтом раскрылся парашют, снизив скорость аппарата с 1500 км/ч до 300 км/ч. Затем был отброшен теплоизолирующий экран, а менее чем за минуту до соприкосновения с поверхностью Марса от защитного кожуха отделилась и посадочная ступень (см. рис. 2). Начиная с этого момента, посадочная ступень должна была направить марсоход по марсианской поверхности — у Curiosity как раз выдвинулись колеса (см. рис. 3.) — отлететь на безопасное расстояние и разбиться. За эти операции также отвечал один из двух экспедиционных компьютеров, расположенный в корпусе самого марсохода.
 Рисунок 2. Посадочная ступень MSL
Рисунок 2. Посадочная ступень MSL
 Рисунок 3. Небесный кран MSL
Рисунок 3. Небесный кран MSL
К Марсу было направлено уже достаточно много космических аппаратов. При этом в каждой следующей экспедиции увеличивался как объем, так и сложность аппаратного и программного обеспечения новых автоматических модулей. Например, в миссии Mars Science Laboratory (Марсианская научная лаборатория) использовалось больше кода, чем во всех предыдущих экспедициях к Марсу, в аппаратах всех стран, бравшихся за реализацию таких проектов. Подобный рост объемов кода, разумеется, представляет собой важную проблему, но такая проблема существует не только в космонавтике. Однако в отличие от большинства других компьютерных программ, встраиваемое ПО для космических модулей проектируется для использования на уникальном оборудовании, взаимодействующем с нетривиальным набором специализированных периферийных устройств. Код разрабатывается всего для одного «пользователя» (конкретной миссии), а на многих критически важных этапах миссии каждая программа используется всего по разу. Например, одним из таких этапов является архиважный процесс приземления, который длится всего несколько минут. Более того, такую программу порой невероятно сложно тестировать, так как этап тестирования должен моделироваться в условиях, максимально приближенных к реальным. Ведь второго шанса не будет. Достаточно самой незначительной ошибки в коде — и мы теряем драгоценную возможность расширить наши познания о Солнечной системе. Кроме того, мы рискуем немалыми вложениями, сделанными в проект, и наносим серьезный ущерб организации, отвечавшей за реализацию проекта.
Снижение риска
Существуют стандартные меры предосторожности, позволяющие снизить степень риска в сложных софтверных системах. В частности, многое зависит от проработки качественной программной архитектуры, в которой четко разграничены сферы ответственности, скрываются данные, обеспечивается модульность, качественно определяются интерфейсы, а также реализуются мощные механизмы отказоустойчивости. Кроме того, совершенно необходим безупречный процесс разработки с четко сформулированными требованиями, отслеживанием соблюдения этих требований, ежедневные интеграционные сборки, тщательное модульное и интеграционное тестирование, а также комплексные имитации будущей работы системы.
В данной статье мы не ставим своей целью заново рассмотреть эти хорошо известные принципы проектирования ПО. Нас значительно более интересуют различные меры предосторожности, предпринятые командой разработчиков ПО, отвечавшей за подготовку программного обеспечения для MSL. Их работа привлекла наше внимание как достаточно нетривиальная. Здесь мы ограничимся исследованием трех конкретных вопросов. Во-первых, поговорим о принятых в этом проекте стандартах написания кода. Такие стандарты известны своей лаконичностью, тщательным учетом рисков и активным использованием инструментов, автоматически проверяющих соответствие кода стандартам. Во-вторых, мы исследуем полностью пересмотренный механизм рецензирования кода, задействованный в этом проекте. Новые методы позволили основательно вычистить от недостатков огромные объемы кода; в этой работе, опять же, активно применялись автоматические инструменты. В-третьих, мы подробно остановимся на логических инструментах проверки моделей. Такие инструменты помогают формализовать верификацию критически важных сегментов кода и нужны прежде всего для выявления дефектов, связанных с параллельной обработкой.
Правила написания кода с учетом рисков. Ни один метод работы не позволяет предотвратить всех ошибок. Тем не менее, следует всеми силами снижать вероятность их возникновения. Однако прежде чем этим заняться, необходимо выяснить, ошибки каких типов возникают в данной предметной области чаще всего. Найти данные несложно. Большинство нештатных ситуаций, возникавших в ходе космических проектов, уже тщательно изучены и документированы, большая часть этой информации общедоступна. Мы уже умеем категоризировать основополагающие причины любой софтверной аномалии и строить список основных проблемных участков работы.
В частности, распространены простейшие ошибки программирования и проектирования, в особенности такие, которые связаны с неаккуратным применением многозадачности. Другие часто возникающие ошибки возникают при использовании динамического выделения памяти. На ранних этапах развития космонавтики такие приемы зачастую были связаны с использованием динамических оверлеев памяти. Наконец, даже стандартные методы защиты таких систем от сбоев характеризовались нежелательными побочными эффектами, которые могли привести к провалу всей миссии.
Стандарт написания кода, созданный на основе результатов данного исследования, отличается от многих аналогичных документов тем, что содержащиеся в нем правила касаются лишь учета рисков, а не каких-либо стилевых аспектов кода. Мы считаем, что стиль написания кода (например, регламентирующий размещение фигурных скобок или форматирование оператора цикла) можно легко откорректировать в зависимости от предпочтений программиста, читающего код (или рецензента этого кода). Такая коррекция выполняется при помощи стандартных инструментов переформатирования кода. Снижение рисков, напротив, является таким фактором, который должен расцениваться как гораздо более важный, нежели правила форматирования. При разработке правил для нового стандарта написания кода, применяемого в ЛРД, мы руководствовались двумя критериями. Во-первых, каждое правило должно напрямую коррелировать с тем или иным наблюдаемым фактором риска, наличие которого подтверждается классификацией аномалий, учтенных при исследовании предыдущих космических проектов. Во-вторых, соответствие любому правилу написания кода должно поддаваться верификации методом инструментальных проверок.
Соответствие стандартам написания кода не должно быть радикальным: «все или ничего». Не весь код является в равной степени важным для приложения. Поэтому в разработанном нами стандарте написания кода различается несколько уровней соответствия, которые применимы к различным типам ПО (см. рис. 4).
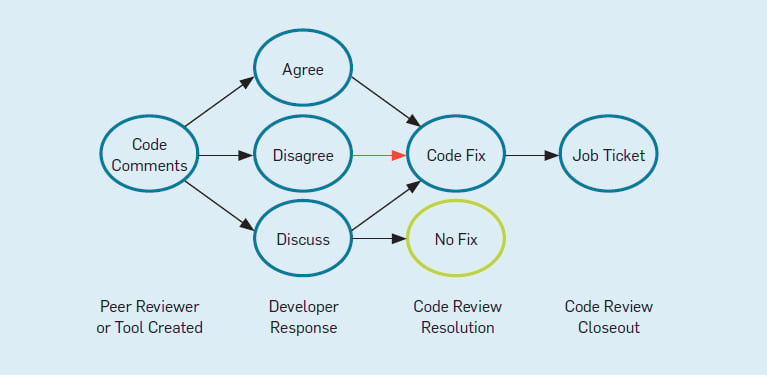
Рисунок 4. Жизненный цикл комментария к коду. Оранжевой стрелкой обозначен момент, в котором разработчик не согласен с внесением изменения в код, но тем не менее по результатам окончательного рецензирования кода это изменение внесено.
Соответствие первого уровня, LOC-1, задает минимальную планку стандарта качества, которому должен удовлетворять весь код, написанный для ЛРД. На этом уровне действует всего два правила. Первое: весь код должен соответствовать нормам конкретного языка программирования. Это означает, что его работа не должна зависеть от таких расширений, специфичных для отдельных компиляторов, которые выходят за рамки базового определения языка. При подготовке программного обеспечения для космических полетов в ЛРД применяется стандарт ISO-C99. Второе правило на этом уровне соответствия требует, чтобы весь код проходил проверку как на уровне компилятора, так и в хорошем статическом анализаторе исходного кода. В ходе такого анализа программа не должна выдавать предупреждений. При тестировании используется компилятор, в котором настроен вывод любых возникающих предупреждений.
Соответствие стандартам второго уровня, LOC-2, предусматривает выполнение правил, обеспечивающих предсказуемое выполнение программы в контексте встраиваемой системы. На данном уровне определяется одно очень важное правило: каждый цикл должен иметь статически верифицируемую верхнюю границу по количеству итераций, которые он может выполнить.
Одно из самых важных правил, необходимых для достижения соответствия уровню LOC-3, связано с использованием утверждений. Изначально мы сформулировали правило, согласно которому каждая функция размером более 10 строк кода должна содержать как минимум одно утверждение. Позже мы пересмотрели его и приняли следующую формулировку: все ПО для обслуживания космического полета и каждый его модуль в отдельности должны иметь плотность утверждений не менее 2 на функцию. Существуют убедительные доказательства того, что сравнительно высокая плотность утверждений коррелирует с низкой плотностью остаточных дефектов. Программное обеспечение, разработанное для обслуживания миссии MSL, имеет общую плотность утверждений в 2,26% на функцию. Данный показатель существенно выше, чем плотность утверждений в более ранних миссиях. Кроме того, он выгодно отличается от аналогичных показателей, описанных в литературе о других проектах. Наконец, последнее изменение, внесенное нами по сравнению с изначальным вариантом стандарта таково: все утверждения оставались в коде и во время полета, тогда как ранее они отключались после тестирования. Теперь утверждение, описывающее сбой, непосредственно связано с системой защиты от отказов. Такая система по умолчанию переводит космический корабль в заранее определенное безопасное состояние, в котором можно аккуратно диагностировать сбой, а потом вернуть систему в нормальный эксплуатационный режим.
LOC-4 — это обязательный стандарт для всего кода, критически важного для выполнения миссии. В проекте MSL к этой категории относится все ПО, работающее на борту корабля. Соответствие этому стандарту ограничивает использование препроцессора C, а также указателей функций и косвенности указателей. Общее количество правил программирования, которые должны выполняться для достижения этого уровня соответствия, остается относительно небольшим — не более 31 правила, связанного с учетом рисков.
Программное обеспечение, отвечающее за безопасность, а также предназначенное для обслуживания пилотируемых полетов, соответствует наиболее строгим стандартам LOC-5 и LOC-6. Эти два наиболее высоких уровня качества также требуют соответствия всем правилам широко известного стандарта программирования MISRA C, в том числе тем, которые не требуется соблюдать при разработке вышеописанных категорий кода.
Мы работали с производителями статических анализаторов кода, в частности, с Coverity, Codesonar и Semmle. Вместе с этими компаниями мы занимались разработкой механизмов автоматической проверки соответствия большинству вышеописанных правил написания кода. Таким образом, соответствие всем правилам, связанным с учетом рисков, может быть проверено автоматически при помощи множества автономных инструментов при каждой сборке программ для MSL.
Приступив к разработке проекта MSL, мы также предприняли дополнительные меры предосторожности. Так, мы ввели новую программу сертификации разработчиков ПО для обслуживания космического полета. В частности, эта программа позволила нам обсудить подробное обоснование всех правил написания кода и закрепить знания методов защитного программирования. Программа сертификации завершалась сдачей экзамена, обязательного для всех разработчиков, занятых написанием или поддержкой ПО для обслуживания космических полетов.
Инструментальное рецензирование кода. Даже самые строгие правила не могут исключить всех дефектов кода. Соответственно, следует разработать как можно больше методов, позволяющих перехватывать дефекты, проскальзывающие в код. Такие средства следует использовать в упреждающем режиме и настолько часто, насколько это возможно. Наш стандартный механизм тщательного рецензирования ПО связан с использованием экспертных проверок. Как правило, в сессии экспертных проверок участвуют опытные разработчики, высказывающие замечания о коде в процессе направленного ознакомления с ним. Этот процесс может быть очень действенным, но только если речь идет об относительно небольших объемах кода. Если в ходе отдельно взятой сессии проверяется более нескольких сотен строк кода, то стремительно снижается эффективность этой сессии. Она выражается в количестве обнаруженных недостатков. При необходимости просмотреть в таком режиме миллионы строк кода мы возлагаем огромную нагрузку на систему, не говоря уже о самих рецензентах.
Эксперты-рецензенты отлично справляются с выявлением недостатков проектирования, но не могут столь же эффективно заниматься проверкой соблюдения более прозаических правил, в частности, соответствия стандартам и недопущения распространенных ошибок при написании кода. К счастью, именно на этом фронте статические анализаторы кода отлично заменяют труд экспертов. Статический анализатор «не устает» вновь и вновь проверять код на наличие одних и тех же дефектов, ночь за ночью, аккуратно информируя нас обо всех обнаруженных нарушениях. Поэтому мы стали активно пользоваться такими технологиями.
На рынке существует большой выбор коммерческих инструментов для статического анализа кода. Каждый из таких анализаторов обладает немного иным набором сильных сторон. Мы обнаружили, что прогон одного и того же кода в нескольких статических анализаторах может быть очень эффективным. Удивительно, насколько незначительно пересекается вывод, выдаваемый различными такими инструментами. Поэтому мы решили в рамках ночной сборки просматривать весь код, написанный для MSL, сразу в четырех разных статических анализаторах кода.
Отобранные нами аналитические инструменты — Coverity, Codesonar, Semmle и Uno — дают при идентификации вероятных багов относительно небольшое количество ложноположительных результатов, эффективно обрабатывают миллионы строк кода и позволяют самостоятельно задавать пользовательские проверки (например, проверять соответствие правилам нашего стандарта написания кода). Вывод каждого инструмента переформатируется и приводится в единообразный вид, эта работа выполняется простыми скриптами постобработки. Поэтому все инструментальные отчеты можно просматривать в едином, не зависящем от производителя инструменте для рецензирования кода. Мы разработали такой инструмент и назвали его Scrub. Программа Scrub предназначена для интеграции вывода статических анализаторов и любых других инструментов фоновой проверки с написанными человеком комментариями, сделанными в ходе экспертного рецензирования. Вся эта информация объединяется в общем пользовательском интерфейсе.
В ходе экспертных проверок рецензенты просили добавлять их замечания к коду в программе Scrub, которая уже предзаполнена результатами статического анализа, полученными в результате последней интеграционной сборки кода. Владелец каждого модуля обязан отреагировать на каждый отчет, составленный как на основе замечаний эксперта-рецензента, так и на основе работы статических анализаторов. Для формулирования таких ответов инструмент Scrub позволяет владельцу модуля выбрать один из трех вариантов:
- "agree" (согласен) — владелец модуля соглашается с замечанием, указанным в комментарии, и берется за устранение найденной проблемы в коде;
- "disagree" (не согласен) — владелец модуля обоснованно полагает, что код написан верно и не должен меняться;
- "discuss" (на обсуждение) — комментарий или отчет сформулирован неясно и требует уточнения перед тем, как можно будет приступить к решению проблемы (см. рис. 5).
 Рисунок 5. Уровни соответствия стандартам написания кода
Рисунок 5. Уровни соответствия стандартам написания кода
Все экспертные проверки кода, а также ответы на все комментарии и отчеты выполняются в оффлайновом режиме, не на собраниях. При каждой экспертной оценке каждого модуля организуется лишь одно очное собрание, на котором разрешаются спорные вопросы, разъясняются отчеты, достигаются компромиссы относительно изменений, которые необходимо внести в код.
В период с 2008 по 2012 годы, когда велась подготовка программного обеспечения для проекта MSL, было проведено 145 обзоров кода. В ходе этой работы было обсуждено около 10 000 экспертных комментариев и 30 000 автоматически сгенерированных отчетов. Около 84% всех комментариев и автоматических отчетов привели к внесению в код тех или иных изменений, связанных с изменением обнаруженных проблем. Ответы категории "disagree" (не согласен) составили всего 12,3% всех откликов, полученных со стороны владельцев модулей. В 33% этих случаев отклики «не согласен» были забракованы на этапе окончательного рецензирования кода, в результате чего требуемые изменения все-таки были внесены в код. Отклик "discuss" (на обсуждение) был получен всего в 6,4% случаев. Примерно в 60% случаев этой категории в код потребовалось вносить изменения.
Данная статистика по рецензированию кода в рамках проекта MSL демонстрирует, что абсолютное большинство экспертных комментариев и полученных в ходе автоматической обработки замечаний практически незамедлительно были внесены в код и не потребовали никакого дополнительного обсуждения в ходе заключительного рецензирования кода. Сэкономленное время позволило нам добиться в ходе рецензирования кода гораздо более существенных результатов, чем в противном случае. Например, мы смогли несколько раз проинспектировать важнейшие модули прежде, чем код был окончательно сдан в эксплуатацию.
Проверка модели. К числу наиболее эффективных видов проверок, которыми мы располагаем для анализа многопоточного кода, относится проверка логической модели. В коде для проекта MSL многопоточность используется достаточно активно. Под контролем операционной системы, работающей в реальном времени, параллельно выполняется 120 задач. Поэтому всегда сохраняется вероятность возникновения условий гонки, которые вызывали заметное количество аномалий в ходе предыдущих космических миссий. Чтобы детально проанализировать код на предмет возможных условий гонки, мы активно применяли инструмент Spin для проверки логических моделей. Вместе с ним использовалась расширенная версия инструмента для извлечения моделей, используемого для обработки кода на C.
Программа Spin была разработана в отделе Computer Science Research компании Bell Labs. Эта работа была выполнена в начале 1980-х, с 1989 года программа Spin находится в свободном доступе. Ранее мы также пользовались этой программой для верификации основных управляющих программных компонентов других космических аппаратов, в частности Cassini, Deep Space One и исследовательских марсоходов. Кроме того, мы применяли эту программу в ходе недавних исследований, направленных на выяснение причин незапланированного ускорения в двигателях Toyota.
Инструмент Spin для проверки моделей специально предназначен для верификации программ, работающих в распределенных системах и имеющих множество потоков выполнения. Его внутренний проверочный алгоритм основан на методе формальной верификации с применением конечных автоматов, сформулированном Варди и Вольпером. Неформально Spin играет роль фонового планировщика процессов и пытается найти такие варианты выполнения кода в системе, которые нарушают требования, заданные пользователем. Простые примеры типов требований, выполнение которых может быть доказано или опровергнуто таким способом — допустимость программных утверждений и отсутствие сценариев, приводящих к возникновению взаимных блокировок. Но возможности программы для проверки моделей этим далеко не ограничиваются. Инструмент может верифицировать осуществимость или неосуществимость значительно более сложных требований, которые могут быть выражены средствами линейной темпоральной логики.
Мы проанализировали ряд критически важных программных компонентов для миссии MSL, в том числе алгоритм управления загрузкой для двух процессоров (определяет, какой из двух процессоров будет контролировать загрузку систем космического корабля), энергонезависимую файловую систему флэш-памяти, а также подсистему управления данными. Несколько уязвимостей, выявленных в ходе этой аналитической работы, удалось устранить до того, как система была пущена в эксплуатацию. Таким образом мы значительно снизили риск возникновения нештатных ситуаций во время полета. Базовая процедура проверки модели программной системы при помощи разработанных нами инструментов может быть проиллюстрирована на небольшом примере. Поскольку правила NASA запрещают публиковать тот код, который используется в системах марсохода, мы используем в данном примере аналогичный общедоступный код из области, не связанной с космонавтикой.
Бывает исключительно сложно выполнить проверку вручную и гарантировать, что конкурентный алгоритм будет работать правильно во всех возможных сценариях выполнения. В качестве примера рассмотрим неблокирующий алгоритм для двусторонних очередей, описанный в работе Detlefs и др (Detlefs, D.L., Flood, C.H., Garthwaite, A.T. et al. Even better DCAS-based concurrent deques. In Distributed Algorithms, LNCS Vol. 1914, M. Herlihy, Ed. Springer Verlag, Heidelberg, 2000, 59–73.). В указанной работе данный код сопровождается четырехстраничным сокращенным доказательством правильности алгоритма. Через несколько лет после данной публикации была предпринята попытка формализовать данное доказательство при помощи программы автоматического доказательства теорем. Эта работа вошла в состав магистерской диссертации. Формализация показала, что как в самом алгоритме, так и в его оригинальном доказательстве имеются недостатки. Правильность изменений, внесенных в алгоритм, поддается проверке системой автоматического доказательства теорем. По данным исследователей, на каждую из двух попыток проверки доказательства — оригинального алгоритма и исправленной версии — ушло по несколько месяцев.
Позже Лэмпорт формализовал оригинальный алгоритм в +CAL (Lamport, L. Checking a multithreaded algorithm with +CAL. In Proceedings of Distributed Computing: 20th International Conference (Stockholm, Sweden, Sept. 18–20). Springer-Verlag, Berlin, 2006, 151–163), доказав, что недостатки алгоритма удается находить гораздо быстрее при использовании программы для проверки моделей. Лэмпорт отметил, что программа проверки моделей TLA+ позволяет получить доказательство менее чем за два дня, причем большая часть работы сводится к описанию формальной модели оригинального алгоритма на языке, поддерживаемом инструментом проверки моделей.
Данный пример демонстрирует, что программа для извлечения моделей также позволяет обойтись без построения формальной модели вручную и выполнять верификацию такого типа на материале фрагментов многопоточного кода в течение минут, а не нескольких дней. Для демонстрации работоспособности этого метода верификации мы использовали оригинальный алгоритм Детлефса. Чтобы найти ошибку в алгоритме при помощи такой программы, достаточно набрать несколько строк кода и выполнить одну команду.
Алгоритм использует атомарную двухсловную инструкцию сравнения с обменом (DCAS). На рис. 6 приведена семантика этой инструкции по Детлефсу. На рис. 7 воспроизведены две процедуры на языке C для добавления элемента в правой части очереди и для удаления элемента с той же стороны. Процедуры добавления и удаления элементов в левой части очереди симметричны вышеуказанным процедурам. В используемой узловой структуре имеется три поля: левый указатель L, правый указатель R и целочисленное значение V.
 Рисунок 6. Семантика инструкции DCAS
Рисунок 6. Семантика инструкции DCAS
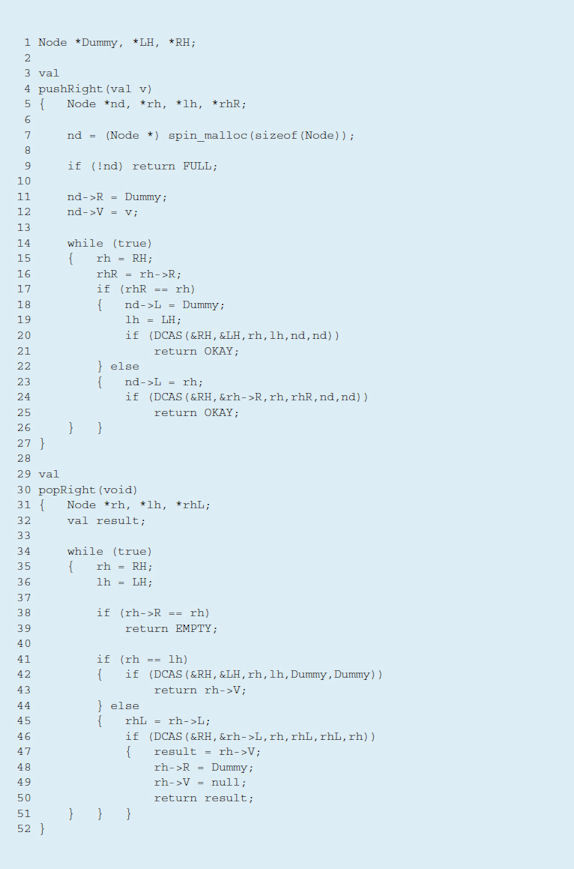 Рисунок 7. Код на языке C для процедур pushRight и popRight
Рисунок 7. Код на языке C для процедур pushRight и popRight
Для верификации кода мы сначала определяем простой тест-драйвер, проверяющий выполнение кода путем добавления и удаления элементов (см. рис. 8). Для упрощения примера мы используем в нем лишь процедуры pushRight() и popRight().
 Рисунок 8. Код на языке C для примерного тест-драйвера
Рисунок 8. Код на языке C для примерного тест-драйвера
В примере с тест-драйвером на рис. 8. записывающий механизм инициализирует очередь в строке 74, а считыватель дожидается, пока этот шаг не будет завершен в строках 57-59. Считыватель содержит в строке 64 утверждение, проверяющее, в правильном ли порядке получены значения, отосланные записывающему механизму, нет ли в них пропусков.
При выполнении данного теста мы можем запускать считыватель и записывающий механизм в разных потоках, однако одни лишь эти тесты не могут доказать правильность алгоритма. Механизм проверки моделей спроектирован так, чтобы подобные проверки выполнялись более тщательно. Если возможны случаи наложения выполнений потоков, способные привести к нарушению утверждения, то программа проверки моделей гарантированно найдет их. Для работы с программой проверки моделей мы определяем небольшой конфигурационный файл, идентифицирующий интересующие нас фрагменты кода. Этот конфигурационный файл также помогает нам определить контекст выполнения для системы, которую мы собираемся верифицировать. Программа извлекает важные фрагменты кода и помещает их в исполняемую систему, которая затем анализируется.
На рис. 9 показан полный конфигурационный файл, необходимый для верификации данного приложения. Первые четыре строки идентифицируют четыре функции в файле исходников dcas.c . Мы хотим извлечь их как инструментированные вызовы функций. В следующих двух строках идентифицируются sample_reader и sample_writer — активные потоки, которые будут вызывать эти функции. В последних трех строках файла исходников определяется заголовочный файл dcas.h, где содержится определение структуры данных Node и имя файла исходников (dcas.c). С этим файлом исходников верификатор должен связываться для получения дополнительных процедур, в частности C-кодировки той функции, которая определяет семантику инструкции DCAS (также см. рис. 6).
 Рисунок 9. Конфигурационный файл Modex
Рисунок 9. Конфигурационный файл Modex
Теперь для верификации алгоритма достаточно выполнить одну команду. При этом будет использоваться инструмент для извлечения моделей Modex и программа для проверки моделей Spin (см. рис. 10).
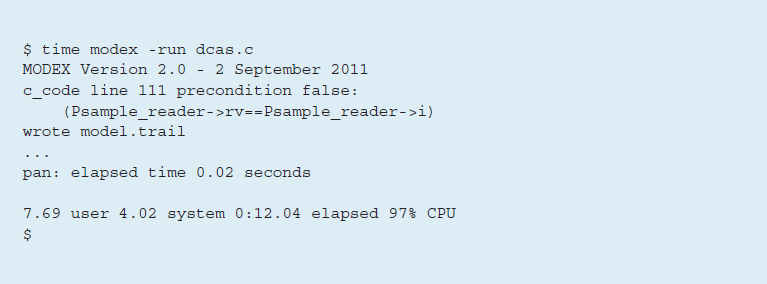 Рисунок 10. Этапы верификации
Рисунок 10. Этапы верификации
На выполнение команды в реальном времени требуется приблизительно 12 секунд, причем сам этап верификации занимает всего 0,02 сек. Оставшееся время исполнения тратится программой для извлечения моделей на генерирование модели верификации из исходного кода, на работу Spin для превращения этой модели в оптимизированный код на языке C и, наконец, на работу компилятора C, собирающего исполняемый файл, который уже осуществляет верификацию. Все эти шаги не требуют дополнительного взаимодействия с пользователем.
При воспроизведении следа ошибок выявляются условия гонки, которые могут привести к нарушению утверждений. Соответственно, алгоритм содержит недостатки (см. рис. 11, 12 и 13). Инструкции, выполняемые записывающим процессом, помечены W, а инструкции, выполняемые считывателем — R. Сначала рассмотрим рис. 11. После исходного вызова initialize в процедуре sample_writer (строка 74 на рис. 8) записывающий механизм инициализирует свой первый вызов pushRight в строке 77, со значением 0. Затем это значение сохраняется (строки 7-19) в процедуре pushRight.
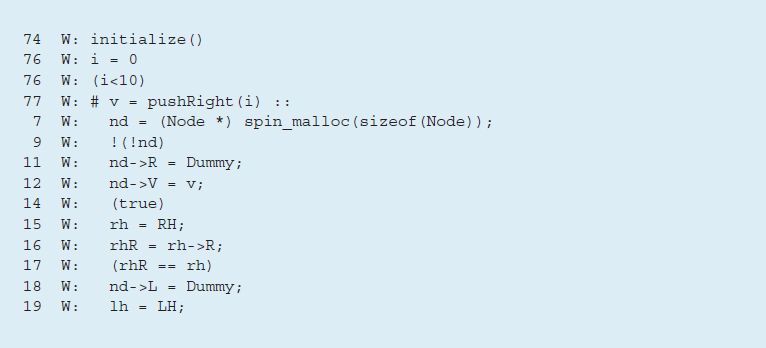 Рисунок 11. Часть 1, частичное выполнение pushRight тестовым записывающим механизмом
Рисунок 11. Часть 1, частичное выполнение pushRight тестовым записывающим механизмом
Следующая инструкция при выполнении pushRight — это вызов DCAS для завершения обновления, но этот вызов может быть отложен. Тем временем, поток sample_reader может продолжать выполнять вызовы к popRight, опрашивая очередь на предмет появления новых элементов (см. рис. 12). Первый вызов (строка 62 на рис. 8) завершается успешно и получает сохраненное значение 0. Оставшиеся шаги на рис. 12 иллюстрируют выполнение процедуры popRight для этого вызова.
 Рисунок 12. Часть 2, вызов popRight тестовым считывателем
Рисунок 12. Часть 2, вызов popRight тестовым считывателем
Этот вызов не должен завершиться успешно, поскольку вызов pushRight, инициированный записывающим механизмом на рис. 11, еще не завершил обновление. Но прерывание уже установлено. Теперь поток sample_reader переходит к следующему вызову после приращения значения i. Этот второй вызов popRight завершается таким же образом, как и ранее, и вновь возвращает значение 0. Происходит ошибка (см. рис. 13).

Рисунок 13. Часть 3, второй вызов popRight считывателем; в этот момент записывающий механизм еще занят выполнением своего первого вызова pushRight, что приводит к нарушению утверждения.
Используемый здесь метод извлечения модели определяется таким образом, что мы можем обойтись очень простыми типами инструментирования в базовых приложениях. Механизм извлечения модели всегда сохраняет исходный поток выполнения задач в приложении. Однако он также позволяет определять в конфигурационных файлах более сложные функции абстрагирования (см. например рис. 9). Такие функции могут использоваться для упрощения извлеченных моделей. Применяемое по умолчанию правило преобразования, требующее однозначного соответствия инструкций из исходного кода и компонентов модели, обеспечивает непосредственную верификацию удивительно крупных многопоточных программ на языке C и алгоритмов.
При подготовке миссии MSL эти возможности автоматизации активно использовались для верификации важнейших многопоточных алгоритмов, с непосредственным использованием их реализаций на C. Для более крупных подсистем мы также вручную создали модели верификации Spin более традиционным образом и проанализировали их. Наиболее крупная из таких подсистем MSL представляла собой критически важный управляющий модуль, реализованный примерно в 45 000 строк кода на языке C. Проект этой подсистемы был вручную преобразован в модель верификации для Spin, реализованную примерно в 1600 строках кода. Работа велась в тесном взаимодействии с проектировщиком модуля. В ходе большинства операций проверки модели удавалось выявить тонкие недостатки, связанные с конкурентностью, и вполне устранимые на уровне кода. В частности, что касается ПО самой файловой системы, проверка моделей стала постоянной составляющей наших регрессионных тестов и выполнялась после внесения в код любых изменений. Мы нередко удивлялись тому, с какой легкостью эта методика позволяла выявлять новые ошибки в коде.
Заключение
Космический корабль MSL безупречно выполнил задачу по доставке аппарата Curiosity на Марс. Операция была осуществлена в 2012 году, и марсоход до сих пор находится на Красной планете, продолжая ее исследовать (рис. 14). Аппарат уже выполнил свою основную задачу, которая сводилась к выяснению того, могла ли в принципе существовать жизнь на Марсе, в сколь угодно отдаленном прошлом.

Рисунок 14. Первые следы аппарата MSL на Марсе
Для максимального повышения шансов на успех миссии были предприняты все необходимые меры, касавшиеся отнюдь не только разработки ПО. Важнейшие аппаратные компоненты дублировались – в частности, на марсоходе установлен дублирующий процессор, идентичный главному. Несложно судить о том, какую важную роль такое дублирование играет для повышения надежности систем. Однако гораздо сложнее заметить, как аналогичная избыточность позволяет повысить и надежность ПО.
Однако мы показали на двух примерах, как программная избыточность использовалась в миссии MSL. Первый пример — акцентирование применения утверждений во всем коде — может показаться тривиальным, но его редко трактуют как защитный механизм, основанный на избыточности. Утверждение всегда должно выполняться. Таким образом, его интерпретация с технической точки зрения практически всегда избыточна. Но иногда происходят почти невозможные вещи — например, непредвиденным образом изменяются внешние условия. Ценность утверждений заключается в том, что они позволяют выявить нештатные условия на максимально раннем этапе процесса выполнения. Механизмы обеспечения отказоустойчивости успевают принять необходимые меры и предотвратить ущерб.
Второй пример программной избыточности связан с обеспечением правильности критически важной последовательности операций при посадке. Это был единственный этап всей операции, на котором были задействованы оба процессора — главный и дублирующий. При выполнении одних и тех же посадочных программ сразу на двух процессорах достигается незначительная защита от программных ошибок. Поэтому были разработаны две независимые версии кода для входа в атмосферу, снижения и приземления. Версия программы, работавшая на резервном процессоре, представляла собой упрощенный вариант того кода, который выполнялся на основном процессоре. На случай неожиданного отказа главного процессора при посадке резервный процессор был запрограммирован взять контроль на себя и продолжить обслуживание посадки по упрощенной модели. Резервная версия программы называлась «второй шанс». К всеобщему облегчению, она оказалась избыточной и так и не выполнялась без главной.
 Здесь приведено содержание «пакета-заполнителя», многократно передававшаяся с марсохода на Землю каждый марсианский день, если аппарат не имел для передачи новых полезных данных телеметрии. В пакете перечислены имена 50 разработчиков из команды ЛРД, а также имена еще 18 человек. Это 18 астронавтов, погибших в результате крушения космических челноков «Челленджер» и «Колумбия», а также при неудачной попытке запуска космического корабля «Аполлон-1». Кроме того, в пакете содержатся слова напутствия от великого астронома Карла Сагана.
Здесь приведено содержание «пакета-заполнителя», многократно передававшаяся с марсохода на Землю каждый марсианский день, если аппарат не имел для передачи новых полезных данных телеметрии. В пакете перечислены имена 50 разработчиков из команды ЛРД, а также имена еще 18 человек. Это 18 астронавтов, погибших в результате крушения космических челноков «Челленджер» и «Колумбия», а также при неудачной попытке запуска космического корабля «Аполлон-1». Кроме того, в пакете содержатся слова напутствия от великого астронома Карла Сагана.
Благодарности
Данное исследование было выполнено в Лаборатории Реактивного Движения (ЛРД) Калифорнийского Технологического института, Пасадена, штат Калифорния. Работа велась по контракту, заключенному с NASA. Благодарности за практически безупречную работу ПО для обслуживания полета миссии MSL причитаются команде выдающихся разработчиков, создавших, проверивших, проанализировавших, протестировавших и повторно протестировавших весь код, потратив на это долгие часы работы.
Автор
Джерард Дж. Хольцманн ([email protected]), старший научный сотрудник, работающий в лаборатории реактивных двигателей NASA в Калифорнийском Технологическом институте, Пасадена, штат Калифорния.
Источник







Релоцировались? Теперь вы можете комментировать без верификации аккаунта.