
Старший системный администратор компании Apalon Михаил Серченя рассказывает об опыте построения отказоустойчивой масштабируемой среды для Web и бэкенда мобильных приложений.
Один из наших продуктов — популярное во всём мире погодное приложение Weather Live, которое доступно на App Store, Mac App Store, Apple Watch, Google Play и Amazon App Store.
Итак, небольшая предыстория.
Я тихо недоумевал от того, что творилось с продакшн-серверами: утомили ночные смс о том, что всё упало и ничего не работает. Было тоскливо от того, что балансировкой занимается BIND, и данные между нодами синхронизировал rsync.
Необходимость перестраивать «прод» была очевидной.
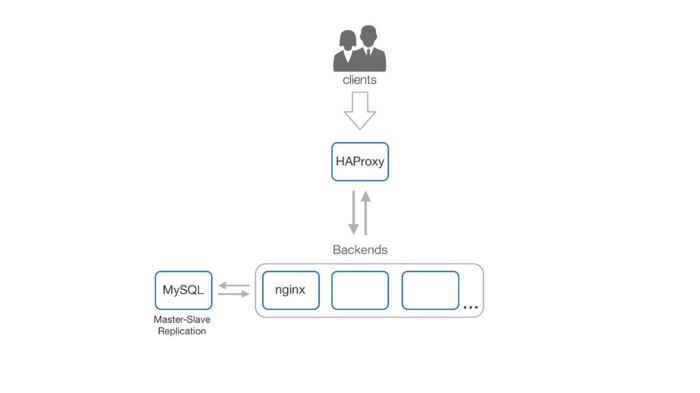
Так была построена нижеописанная схема:
- точка входа haproxy x 2 + keepalived —- и нам не страшно потерять 1 баланс;
- маршрутизация клиентских запросов — кто-то уходит за статикой в varnish, кто-то за динамикой на бэкенды;
- кэширование объектов при помощи varnish;
- S3-подобное отказоустойчивое хранилище на базе Ceph для хранения контента.
Строили всё по нарастающей, от точки входа. Первое — это балансировка клиентских запросов и единая точка входа. С данной задачей отлично справляется HAProxy (далее HAP). Его плюсы:
- Open source, он имеет несколько типов балансировки, таких как roundrobin, source, leastconn.
- Проверка состояния бэкендов. Можно манипулировать заголовками реквестов, как входящих так и исходящих.
- Маршрутизация запросов.
- Защита от DDoS.
Теперь обо всём по порядку.
Мы поставили HAP, у нас есть какая-то защита от DDoS, балансировка, но нет отказоустойчивости. Умер HAP — всё «упало». Что же делать? Как подстраховаться на такой случай? Было решено добавить дублирующий HAP.
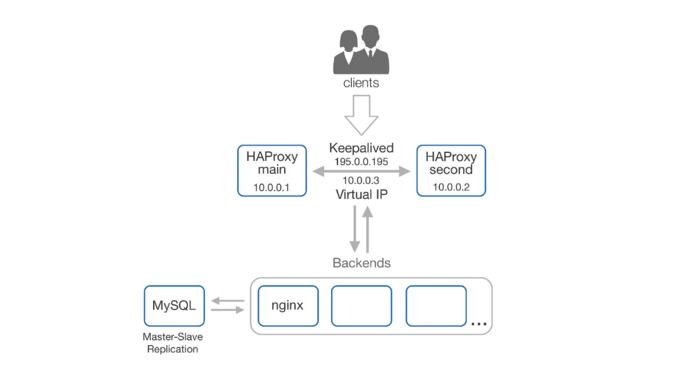
В такой схеме нам нужен один IP, который будет мигрировать между двумя HAP в зависимости от состояния. С этой задачей нам поможет справится Keepalived и VIP (виртуальные IP-адреса; ваш провайдер должен поддерживать multicast!). Теперь, в случае падения главного баланса, всю нагрузку на себя автоматически примет запасной баланс, а Keepalived отправит нам письмо о том, что перешёл в master state.
Далее по схеме переходим к бэкендам. Это сервера с Linux на борту, в роли фронта — Nginx, за ним могут быть php-fpm, unicorn, puma.
Наша задача — иметь одинаковый код и контент на всех нодах, и хорошо бы иметь двухстороннюю синхронизацию. Главное — не получить единую точку отказа, помните?
Где-то в конце 2012 года я нашел проект Lsyncd — это демон синхронизации, написанный на Lua. Данные синхронизируются при помощи того же rsync, но все события он берёт из inotify, который мониторит изменения в файловой системе. Конфигурация простая, не вызовет сложностей. После запуска на всех нодах имеем одинаковый код. Изменили на одной ноде — изменилось на всех.
У lsyncd есть свои минусы, но о них мы поговорим чуть позже.
Теперь возникает вопрос с базами данных. У нас классическая схема master-slave репликация: упал мастер — всё упало. У меня в практике такое было один раз, когда умер райд-контроллер. Это, конечно, не конец света — у нас же есть слейв, можем поменять местами и дальше работать. Но это дает downtime, наши сервисы не работают, клиенты злые, боссы злые, и вообще все злые.
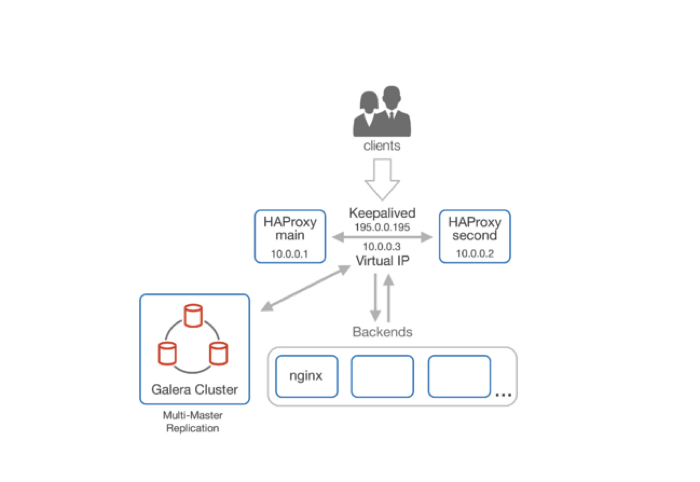
Но по факту и это невелика беда. Есть замечательный проект Percona xtradb cluster(PXC), который позволяет нам иметь multi-master replication.
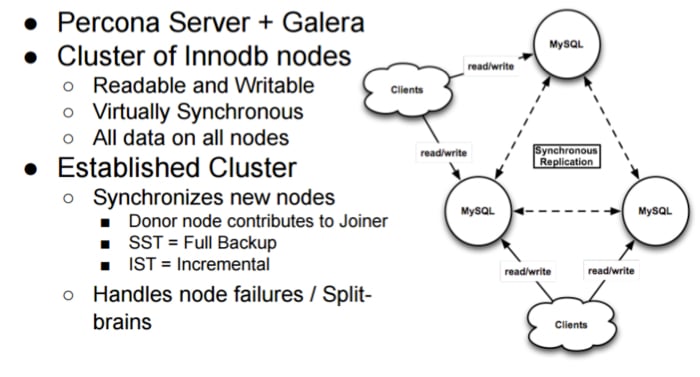
Percona XtraDB Cluster features include:
- Synchronous replication
- Multi-master replication support
- Parallel replication
- Automatic node provisioning
Детально рассказывать о PXC не буду — тема очень обширная и достойна отдельного доклада. Упомяну только основные моменты.
Нам необходимы три ноды, чтобы они могли определиться, кто «главный». Далее все таблицы должны содержать primary key. Движок — только innodb, myisam поддерживается только в экспериментальном режиме и не готов для «прода».
Можно читать и писать в каждую ноду. Использовать проверку на доступность и балансировку средствами вашего приложения, которое будет обращаться к базе или же свалить эту задачу на плечи HAP, с которой он отлично справляется. Именно так и сделано в нашей схеме. В HAP мы открываем порт 3306 и все входящие на него запросы проксируем в PXC, также HAP проверяет на доступность каждую ноду. Ниже приведён пример из конфигурационного файла HAP.

Для проверки доступности мы обращаемся на порт 9200. На нём слушает xinetd, который при обращении запускает bash-скрипт проверки состояния ноды. Если кому-то будет интересно установить PXC, есть пошаговая инструкция на percona.com.
Подведем промежуточный итог: у нас есть масштабируемость и отказоустойчивость на всех узлах нашей схемы. Настало время доставать напильник, в роли которого в нашей схеме выступят Ceph и Varnish.
Ранее я говорил что у lsyncd есть минусы. Так вот, если у вас большое количество файлов (300-800 тысяч и больше), то после перезапуска сервиса он может подниматься минут 45 — пока перечитает содержимое всех каталогов и выполнит первоначальную синхронизацию. Также у нас огромная избыточность: сколько нод в кластере бэкендов, столько же дублей объектов. В итоге — иррациональное использование дискового пространства, повышение стоимости серверов.
Долго выбирал между разными вариантами кластерных FS c отказоустойчивостью и масштабированием и в итоге остановился на Ceph. И вот почему:
- производительность
- масштабируемость
- отказоустойчивость
- самовосстановление после сбоя
- настраиваемая избыточность
- нет привязки к вендору
- можно использовать готовый AWS SDK для S3.
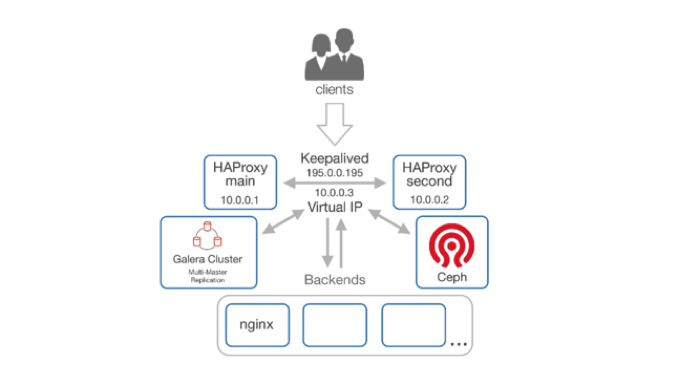
В данной схеме Ceph используется как объектное хранилище, по своим функциям похож на Amazon S3. Развернуть его можно двумя способами. Для этого можно использовать Python-скрипт Ceph-deploy либо мануально.
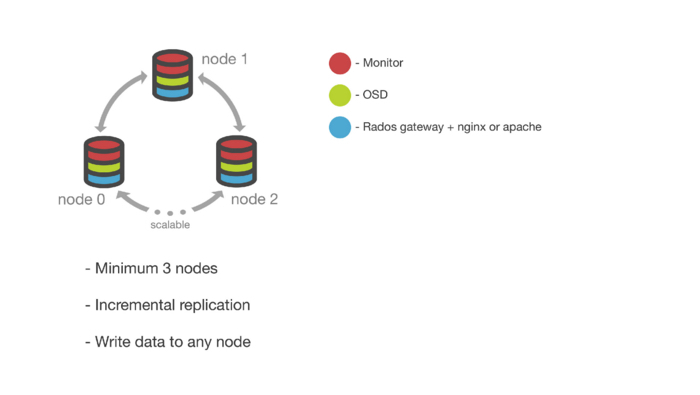
Готовый кластер представляет собой три и более нод, на каждой из которых мы имеем:
- Monitor — обеспечивает адресацию данных внутри кластера и хранит информацию о состоянии и распределении данных внутри хранилища.
- OSD (object storage daemon) — сущность, которая отвечает за хранение данных, основной строительный элемент кластера Ceph.
- Rados gateway — вспомогательный демон, исполняющий роль прокси для поддерживаемых API объектных хранилищ.
- Nginx — в роли фронта.
Важно помнить, что нам необходим хороший канал связи между нодами. В идеале это «оптика», но на практике всё отлично работает по «меди» и на гиговом канале.
Итак, мы настроили наш Ceph, набрали команду Ceph -s и увидели заветное HEALTH_OK. Теперь у нас есть свой simple storage service. Переносим в Ceph всю статику (музыку, картинки, видео и т.д.), тем самым высвобождая место на наших бэкендах, избавляемся от чрезмерной избыточности, экономим место на дисках и позволяем намного быстрее стартовать lsyncd. У меня это время сократилось примерно до 5 минут.
Теперь лакируем нашу схему, чтобы всё было гладко и ровно, добавляем Varnish.
Пару слов о том, что это такое. Varnish Cache — это web accelerator, так же известный как кэширующий HTTP reverse proxy. Varnish позволяет значительно сократить latency при отдаче статики, а также разгрузить ваши бэкенды.
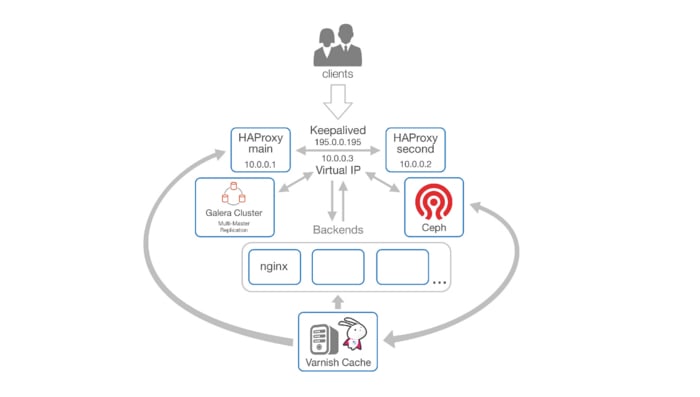
Вот пример того, как Varnish позволил снизить la (load average), на одном из наших проектов.
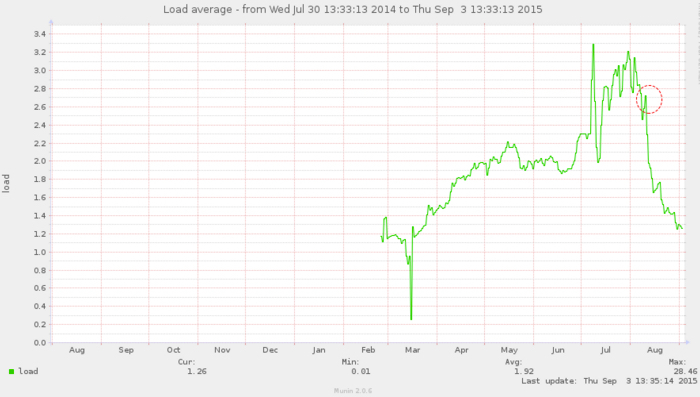
Время ответа упало с 486ms до 75ms.
Было:

Стало:

Здесь нам необходимо внести некоторые правки в конфиг-файл haproxy.
Нужно описать маршруты, куда и при каких условиях мы будем адресовать клиентский запрос. По факту, тут всё просто, если у нас запрос на картинку. Определяем path_end ( .jpg .gif .png .css .js .htm .html .xml .json .txt), если есть совпадение, перенаправляем наш запрос на Varnish, он в свою очередь проверит, есть ли у него кэш данного объекта. Если есть — отдаёт, если нет — идёт за этим объектом либо в Ceph, либо на наши бэкенды, помещает объект в кэш и отдаёт его пользователю. Что касается ситуации с выходом из строя самого Varnish, то ничего критичного не произойдет. Все запросы будут адресованы напрямую бэкендам или в Ceph. Можно спокойно добавить второй кэширующий сервер.
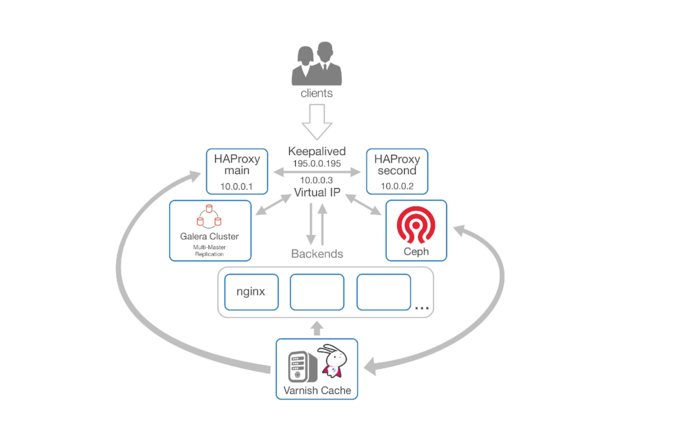
А теперь итоги:
- у нас нет единой точки отказа;
- мы можем в любой момент горизонтально масштабировать нашу схему;
- у нас есть объектное S3-подобное хранилище;
- низкая задержка при ответе;
- отказоустойчивая реплицируемая multi-master sql база данных.
Буду рад ответить на ваши вопросы в комментариях.
*Мнение колумнистов может не совпадать с позицией редакции.







Релоцировались? Теперь вы можете комментировать без верификации аккаунта.